Vì sao có Index mà câu SQL vẫn chậm
Trong hành trình tối ưu các dự án của mình, có lẽ một trong những băn khoăn mà tôi thấy ở nhiều anh em Dev nhất đó là, tại sao câu lệnh SQL của tôi đã có Index rồi, đúng trường tìm kiếm rồi mà nó vẫn chậm thế.
Tôi viết bài này để chia sẻ những góc nhìn cách mà Database hoạt động, giúp anh em hiểu rõ bản chất hơn về tối ưu. Không phải cứ “Index thần chưởng” là sẽ giải quyết được hiệu năng
1. Bản chất của Index sinh ra để giảm số lượng I/O cần thực hiện
Thông thường các câu lệnh SQL của anh em sẽ làm việc trên Table trong Database đúng không nào.
Nhưng Table đó thực ra chỉ là 1 khái niệm về logic.
Các dữ liệu thật sự của nó được lưu trữ trên những Data File vật lý (ở trên hệ điều hành của mình, anh em có thể vào nhìn thấy tên của các File đó).
Bản chất của 1 câu lệnh SQL khi gửi tới Database, nó sẽ phải thực hiện một loạt hành động I/O để lấy dữ liệu từ các Data File trên.
Hiểu một cách ngắn gọn thì câu lệnh nào I/O nhiều thì thường sẽ bị chậm.
Và Index sinh ra với mục tiêu làm giảm số lượng I/O đó.
Anh em Dev khi viết lệnh ít người để ý rằng câu lệnh của mình đã khiến Database phải thực hiện I/O như thế nào, nên đôi khi không mường tượng rõ về mức độ tác động tới hệ thống.
Tôi sẽ demo luôn việc kiểm tra hiệu năng chính xác của một câu lệnh khi gửi tới Database cho anh em nhé
Tôi có 1 bảng Users với 2.465.713 bản ghi (tôi giả lập cả trên Database Oracle và SQL Server với cùng tập dữ liệu, cùng cấu trúc luôn). Bảng này lưu thông tin của các người dùng trao đổi trên Stackoverflow phục vụ cho việc Lab nhé anh em.
1.1. Kiểm thử hiệu năng Index trên SQL Server
Tôi muốn đánh giá xem câu lênh tìm kiếm thông tin Users có số Upvotes trên các bài viết của họ lớn hơn 5000
select * from users where Upvotes > 5000
Để biết chính xác câu lệnh này khi thực hiện chiếm tài nguyên I/O thế nào trên SQL Server, tôi thực hiện lệnh sau trước khi thực hiện câu SQL
set statistics io on
Lúc này ở phần Messages, anh em sẽ thấy thông số chi tiết thực hiện của câu SELECT bên trên.
(921 rows affected)
Table 'Users'. Scan count 1, logical reads 44530, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 24, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Giải thích ý nghĩa một số cột quan trọng:
- Thông số này cho biết câu lệnh có 921 bản ghi thỏa mãn điều kiện (lọc ra được từ 2.465.713 bản ghi của table Users)
- Scan count 1 điều này thể hiện SQL Server chỉ thực hiện một lần QUÉT (SCAN) truy xuất vào Table Users. (Trong SQL Server, cái Table này còn có thể được hiểu như Clustered Index). Trong trường hợp câu lệnh của anh em có những phép Join, số lần Scan count này sẽ tăng lên, nó có thể cho ta biết số lần loop mà SQL Server cần thực hiện cho phép join đó. Hiểu một cách dễ hơn, ông SQL Server chỉ cần truy xuât 1 lần vào table Users là tìm được yêu cầu của query rồi, không phải đọc đi đọc lại nhiều lần làm gì cả.
- Logical Reads 44530. Đây chính là số lượng dữ liệu mà Database cần phải đọc từ đống Data File vật lý để đưa lên RAM. Đơn vị đo ở đây thể hiện số PAGE (đơn vị nhỏ nhất chứa dữ liệu mức vật lý, trong các Database có thể gọi tên thuật ngữ khác nhau, ông gọi là PAGE, ông gọi là BLOCK, nhưng cùng 1 ý nghĩa). 1 Page = 8KB (thường là thế, trừ khi ông nào cố tình cấu hình kỳ dị, nâng cao).
- Do mỗi Page = 8KB, nên tổng số dữ liệu mà câu lệnh này cần thực hiện là 44530 pages x 8 KB = 356.240 KB tức là khoảng 347.8 MB
- Ghi chú ở đây: Logical Reads là một thông số rất quan trọng, số này càng nhiều chứng tỏ hệ thống phải thực hiện load càng nhiều dữ liệu lên RAM
- physical reads = 0. Điều này thể hiện toàn bộ dữ liệu mà SQL Server cần đều có trên RAM, nó không cần thực hiện thao tác đọc xuống Data File (ở trên Disk). Sẽ có một số trường hợp khi anh em chạy câu lệnh lần đầu tiên thì thấy physical reads > 0, sau đó chạy lại thì thấy physical reads = 0, điều này có nghĩa là những dữ liệu cũ đã được cache nhé anh em.
- lob logical reads = 24. LOB thể hiện cho các dữ liệu của cột dạng như NVARCHAR(MAX). Thông số này cho biết câu lệnh có 24 page chứa dữ liệu LOB được đọc trong RAM (cái này tương đương 24 pages * 8KB = 192 KB dữ liệu LOB được đọc). Anh em để ý thì cột Aboutme của table Users có kiểu dữ liệu là dạng LOB nhé.
Để hiểu hơn tại sao có các thông số này, chúng ta cần xem chiến lược thực thi mà câu lệnh đã được thực hiện trong Database.
Chiến lược thực thi chính là các bước thực thế mà Database Engine đã lựa chọn để thực hiện, gần như anh em làm dự án tối ưu sẽ đều phải đụng tới vấn đề này.

Ý nghĩa của chiến lược thực thi trên như sau:
- SQL Server sẽ cần thực hiện quét toàn bộ dữ liệu trên Clustered Index PK_Users_Id của bảng Users.
- Tại đây, bản chất của Clustered Index chính là toàn bộ dữ liệu của bảng nhưng được sắp xếp lại theo chiều của cột ID. Do đó quét toàn bộ Clustered Index chính là quét toàn bộ bảng.
Kiểm tra dung lượng của bảng Users đang chiếm bao nhiêu MB trên vật lý, tôi thấy kết quả như sau anh em ạ
.webp)
Data Space = 347. 109 MB.
Dung lượng này cũng tương đương với số lượng I/O mà đo được trong thông số khi bật Statistics IO bên trên.
Thông thường, anh em Dev chúng ta sẽ thêm Index trên điều kiện tìm kiếm để giúp câu lệnh nhanh hơn.
Tôi cũng sẽ thử làm vậy xem sao.
Tạo Index trên cột Upvotes
create index idx_upvotes on users(upvotes)
Kiểm tra lại chiến lược thực thi và thông số I/O sau khi có Index nhé anh em.
Chiến lược thực thi lúc này

Aha, lúc này SQL Server thay vì quét toàn bộ Clustered Index (chính là quét toàn bộ Table Users), nó đã sử dụng được Index của chúng ta mới tạo ra.
Và trong SQL Server, nếu anh em để ý thì cái mũi tên ở phần chiến lược thực thi này nó cũng NHỎ HƠN đấy, điều này thể hiện lượng dữ liệu ở bước đó sẽ ít đi nhá.
Thông số I/O chi tiết tại khi chạy với Index đã được giảm hẳn, cụ thể như sau
(921 rows affected)
Table 'Users'. Scan count 1, logical reads 2834, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 24, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Số logical reads đã giảm từ 44530 (pages) xuống còn 2834 (pages).
Quả thật Index tạo ra với mục tiêu là giúp câu lệnh SQL giảm được số lượng I/O cần thực hiện
Bây giờ tôi sẽ kiểm thử trên Oracle Database, để xem mọi thứ có khác gì không nhé.
1.2. Kiểm thử hiệu năng Index trên Oracle Database
Tôi cũng thực hiện câu lệnh tương tự như tình với với SQL Server.
Để kiểm tra cụ thể chiến lực thực thi và số lượng I/O đã thực hiện trên Oracle Database, tôi sử dụng cách thức cụ thể như sau
SQL> set autotrace traceonly
SQL> select * from users where Upvotes > 5000;
Kết quả của câu lệnh này
921 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3461732445
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 920 | 119K| 13612 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| USERS | 920 | 119K| 13612 (1)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("UPVOTES">5000)
Statistics
----------------------------------------------------------
166 recursive calls
0 db block gets
51051 consistent gets
49210 physical reads
0 redo size
760148 bytes sent via SQL*Net to client
268743 bytes received via SQL*Net from client
1829 SQL*Net roundtrips to/from client
11 sorts (memory)
0 sorts (disk)
921 rows processed
Chiến lược thực hiện của Oracle cũng tương tự như với SQL Server, nó phải thực hiện quét toàn bộ dữ liệu của table Users.
Điều này thể hiện ở phần TABLE ACCESS FULL trong kết quả bên trên
Các thông số Statistics bên dưới cho ta thông tin cụ thể hơn về tài nguyên của câu lệnh
- recursive calls = 166: Đây là số lần mà Oracle cần phải thực hiện ngầm các câu lệnh nội bộ. Kiểu như nó phải kiểm tra nơi lưu thông tin metadata để biết được Users là Table hay là View, bảng Users này có cấu trúc thế nào thì nó cũng cần phải kiểm tra thông tin metadata mới biết được.
- db block gets = 0. Thông số này thể hiện có các block dữ liệu đang được cập nhật không, phần này > 0 khi chúng ta thực hiện các thao tác chỉnh sửa dữ liệu (các câu lệnh DML).
- consistent gets = 51051. Thông số này thì tư tưởng cũng giống như cái Logical Reads trong SQL Server mà tôi phân tích bên trên. Đây là số lượng block (ở Oracle gọi tên thế, còn SQL Server mấy ông ấy gọi là Pages, cả 2 cái mặc định đều có kích thước là 8KB cho một đơn vị page/block). Vậy số dữ liệu mà Oracle đã thực hiện việc đọc từ Memory sẽ là 51.051 * 8KB ~ 398 MB dữ liệu.
- physical reads = 49210. Thông số này cho biết Oracle đã thực hiện đọc trực tiếp từ Disk vì dữ liệu này chưa có trong buffer cache. Số lượng dữ liệu phải đọc từ Disk ở đây tính ra là 49.210 block * 8KB = 393.680 KB tức là khoảng 384MB
- redo size = 0. Vì đây là câu lệnh SELET, nên dữ liệu không có gì thay đổi cả, do đó không có bất kỳ thông tin nào sinh ra trong redo log. Khi anh em dùng câu lệnh DML thì cái số này sẽ > 0
Bây giờ tôi sẽ tạo Index để xem số lượng I/O thay đổi thế nào nhá.
Thực hiện câu lệnh tạo Index trên cột Upvotes
SQL> create index idx_upvotes on users(upvotes);
Index created.
Thực hiện lại câu lệnh
SQL> set autotrace traceonly
SQL> select * from users where Upvotes > 5000;
Thông số bây giờ như sau:
SQL> select * from users where Upvotes > 5000;
921 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1598083519
--------------------------------------------------------------------------------
-------------------
| Id | Operation | Name | Rows | Bytes | Cost
(%CPU)| Time |
--------------------------------------------------------------------------------
-------------------
| 0 | SELECT STATEMENT | | 920 | 119K| 24
4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| USERS | 920 | 119K| 24
4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_UPVOTES | 920 | |
4 (0)| 00:00:01 |
--------------------------------------------------------------------------------
-------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("UPVOTES">5000)
Statistics
----------------------------------------------------------
2 recursive calls
0 db block gets
2750 consistent gets
94 physical reads
0 redo size
760649 bytes sent via SQL*Net to client
268743 bytes received via SQL*Net from client
1829 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
921 rows processed
Số lượng I/O đã giảm đúng theo phong cách “tụt huyết áp”
- Số physical Reads chỉ còn 94
- Phần consisten gets đã giảm 51051 xuống còn 2750
Và chiến lược thực thi cho thấy câu lệnh giảm được tụt huyết áp là do đã dùng Index IDX_UPVOTES
2. Sự thật về cách Database chọn Index
Anh em đều đã được thấy tác dụng của Index bên trong ví dụ trên rồi, không có gì bàn cãi về lợi ích tuyệt vời ấy cả.
Tuy nhiên chúng ta cần hiểu là không có một loại thuốc nào dùng trong mọi trường hợp đều khỏi cả.
Mấy ông Database Engine cũng biết như vậy, nếu như Index giúp cải thiện được I/O thì tôi sẽ dùng Index.
Còn các trường hợp Index mà không giúp I/O giảm đi thì sao ?
Hiển nhiên là Database Engine sẽ không chọn nói.
Đơn giản thế thôi
Tôi sẽ ví dụ ngay với anh em trường hợp cụ thể sau.
Giả sử cũng là câu lệnh bên trên thôi, nhưng tôi không muốn tìm những người có Upvotes lớn hơn 5000 nữa, tôi muốn tìm tất cả mọi người có Upvotes > 50 thôi.
Hãy thử xem có bao nhiêu người thỏa mãn điều kiện này nhé.
select count(*) from users where Upvotes > 50
214068
Hơn 214K Users thỏa mãn (chiếm gần 9% tổng số dữ liệu trong bảng Users). Số lượng bản ghi thỏa mãn điều kiện lọc lúc này cũng lớn hơn 233 lần so với 921 bản ghi thỏa mãn (khi tìm theo điều kiện Upvotes > 500).
Khi số lượng bản ghi thỏa mãn chiếm một lượng lớn, thì ngay cả trên cột tìm kiếm đó đã có Index, các Database cũng sẽ lựa chọn quét toàn bộ Table và bỏ qua Index anh em ạ.
Kiểm tra phát thấy ngay.
Chiến lược thực thi và thông số I/O trên SQL Server nè

Thông số I/O chi tiết
(214068 rows affected)
Table 'Users'. Scan count 1, logical reads 44530, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 162, lob physical reads 1, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Còn đây là minh chứng trên Oracle Database
SQL> select * from users where Upvotes > 50;
214068 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3461732445
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 204K| 25M| 13613 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| USERS | 204K| 25M| 13613 (1)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("UPVOTES">50)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
453392 consistent gets
130715 physical reads
0 redo size
154076418 bytes sent via SQL*Net to client
58017928 bytes received via SQL*Net from client
409378 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
214068 rows processed
Anh em thấy không, FULL TABLE SCAN ngay anh em ạ.
Không có bất kỳ dấu hiệu nào của Index dám bén mảng tới đây cả.
TÔI VẪN NGHĨ LÀ NẾU DÙNG INDEX THÌ SẼ NHANH HƠN !!!!!
Sẽ có anh em vẫn nghĩ thế, vẫn akay là nếu dùng Index có khi ngon hơn hẳn.
Tôi sẽ thực hiện demo việc ép Database phải dùng Index để xem kết quả ra sao nhé
2.1. Demo ép SQL Server bắt buộc sử dụng Index (WITH (INDEX))
Chúng ta có thể bắt chiến lược thực thi phải “làm theo ý của mình” bằng cách sử dụng WITH (INDEX).
Cách thức cụ thể như sau
SELECT *
FROM Users WITH (INDEX(idx_upvotes))
WHERE Upvotes > 50;
Lúc này anh em sẽ thấy chiến lược của SQL Server đã sử dụng Index IDX_UPVOTES thay vì quét toàn bộ clustered index như ban đầu
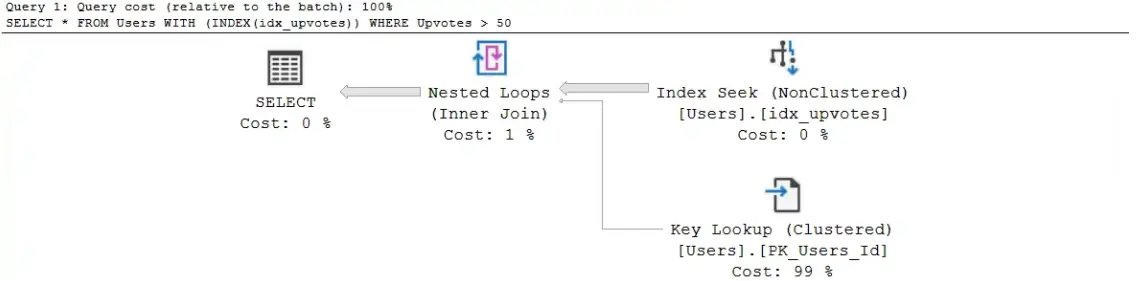
Tuy nhiên khi lựa chọn cách thức này, thông số I/O của câu lệnh lại tăng vọt lên như sau:
(214068 rows affected)
Table 'Users'. Scan count 1, logical reads 655966, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 162, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Thông số logical reads tăng từ 44530 lên 655966 (tăng hơn 14.7 lần !!)
Như vậy, nếu dùng Index, tài nguyên cần sử dụng của câu lệnh này cao chót vót luôn.
Chứng tỏ SQL Server lựa chọn không dùng Index là chuẩn.
2.2. Demo ép Oracle bắt buộc sử dụng Index (HINT /*+ INDEX */)
Trong Oracle, anh em có thể dùng cú pháp sau để khiến một câu lệnh SQL buộc phải dùng Index (thuật ngữ người ta gọi là HINT anh em nhé):
SELECT /*+ INDEX(u IDX_UPVOTES) */ *
FROM users u
WHERE upvotes > 50;
Chiến lược thực thi và thông số thống kê I/O khi sử dụng Index như sau:
Execution Plan
----------------------------------------------------------
Plan hash value: 1598083519
--------------------------------------------------------------------------------
-------------------
| Id | Operation | Name | Rows | Bytes | Cost
(%CPU)| Time |
--------------------------------------------------------------------------------
-------------------
| 0 | SELECT STATEMENT | | 204K| 25M| 5351
6 (1)| 00:00:03 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| USERS | 204K| 25M| 5351
6 (1)| 00:00:03 |
|* 2 | INDEX RANGE SCAN | IDX_UPVOTES | 204K| | 38
5 (1)| 00:00:01 |
--------------------------------------------------------------------------------
-------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("UPVOTES">50)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
623446 consistent gets
1779 physical reads
0 redo size
153068999 bytes sent via SQL*Net to client
58017958 bytes received via SQL*Net from client
409378 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
214068 rows processed
Cũng tương tự như trong trường hợp của SQL Server, anh em sẽ thấy thông số của Oracle cao hơn ban đầu
Thông số consistent gets đã tăng từ 453392 lên 623446 (tăng 1.37 lần)
3. Vậy bản chất tại sao có Index rồi mà câu lệnh SQL vẫn chậm
Trong các trường hợp khi anh em gặp 1 câu lệnh SQL đang “chạy như rùa”, và muốn cải thiện tốc độ bằng cách thêm Index, hãy đảm bảo một việc rằng
Kiểm tra chiến lược thực thi của câu lệnh ấy trước sau khi thêm Index
Đến cuối cùng, bản chất của việc câu lệnh có nhanh hơn hay không sẽ nằm ở chiến lược thực thi (SQL Execution Plan).
Việc chúng ta có thêm Index, chỉ là đưa thêm 1 lựa chọn khi Database Engine quyết định nên chọn chiến lược nào để thực hiện câu lệnh.
Trong quá trình cân nhắc tất cả các phương án, Database hoàn toàn có thể bỏ qua Index, giống như trong demo bên trên của tôi.
Nếu anh em rơi vào hoàn cảnh chúng ta tìm kiếm mà lượng dữ liệu trả ra chiếm đa số của Table, thì thường có đánh Index thì câu ấy vẫn chậm thôi (vì Database đã chọn quét toàn bộ bảng).
Index không phải là cây đũa thần đâu anh em ạ
Chốt hạ mấy thứ sau anh em cần nhớ
- Luôn luôn xem chiến lược thực thi của một câu lệnh khi tối ưu.
- Index không phải lúc nào cũng hiệu quả.
Nếu anh em muốn đọc sâu hơn về chiến lược thực thi cũng như các tình huống tối ưu thực tế, anh em có thể xem thêm:
- Bài viết tình huống hiệu năng tự nhiên chênh lệch hàng trăm lần trên SQL Server: Click vào đây →
- Vấn đề hiệu năng tương tự trên MongoDB: Click vào đây →